Redis (Phần 2) - Kiến trúc và khả năng mở rộng
Trong Phần 1, chúng ta đã hiểu tại sao Redis lại nhanh và cách nó hoạt động bên trong. Nhưng ở môi trường production thực tế, chúng ta hiếm khi chỉ chạy một con Redis duy nhất.
Nếu con Redis đó sập (chết phần cứng, đứt cáp mạng), toàn bộ ứng dụng của bạn sẽ đi đứt. Hoặc nếu dữ liệu phình to lên 500GB, một con server không thể gánh nổi.
Đây là lúc chúng ta cần nói về Kiến trúc của Redis.
Phần II: Các mô hình kiến trúc Redis
1. Mô hình Master-Replica (Replication)
Để giải quyết vấn đề mất dữ liệu hoặc sập server khi chạy một con Redis duy nhất, khái niệm Replication ra đời.
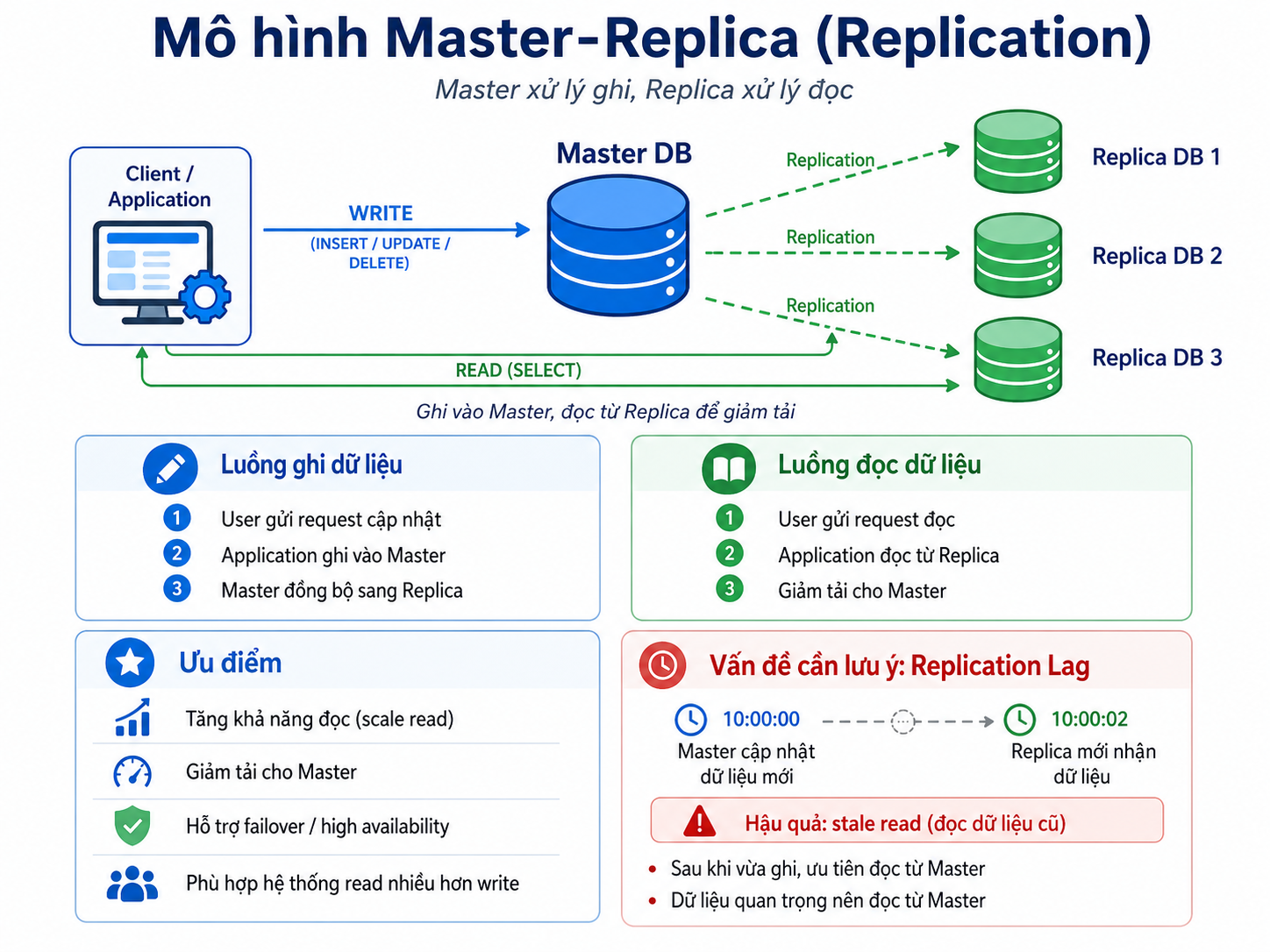
Cách hoạt động:
- Có 1 node chính gọi là Master và 1 (hoặc nhiều) node phụ gọi là Replica (trước đây gọi là Slave).
- Master chịu trách nhiệm nhận Write (lệnh ghi) và Read (lệnh đọc).
- Dữ liệu từ Master sẽ được đồng bộ (sync) không đồng bộ sang các node Replica.
- Ứng dụng có thể đọc (Read) từ các Replica để giảm tải cho Master.
Ưu điểm:
- Giảm tải đọc (Read scaling): Bạn có thể có 3 node Replica để chia sẻ truy vấn đọc.
- Dự phòng dữ liệu (Redundancy): Nếu Master chết, dữ liệu vẫn còn nằm an toàn bên phía Replica.
Nhược điểm:
- Không tự động chuyển đổi (No Automatic Failover): Nếu Master sập, hệ thống vẫn "chết" ở khâu Write cho tới khi bạn thức dậy lúc 3h sáng và tự tay gõ lệnh biến một node Replica thành Master mới.
- Đồng bộ bất đồng bộ (Asynchronous replication): Có thể xảy ra mất mát một lượng nhỏ dữ liệu vừa ghi nếu Master chết trước khi kịp đồng bộ sang Replica.
1.1 Vấn đề Data Consistency (Tính nhất quán dữ liệu)
Trong kiến trúc Master-Replica của Redis, quá trình nhân bản (replication) mặc định là bất đồng bộ (asynchronous). Điều này dẫn đến các thách thức về Data Consistency (Tính nhất quán dữ liệu):
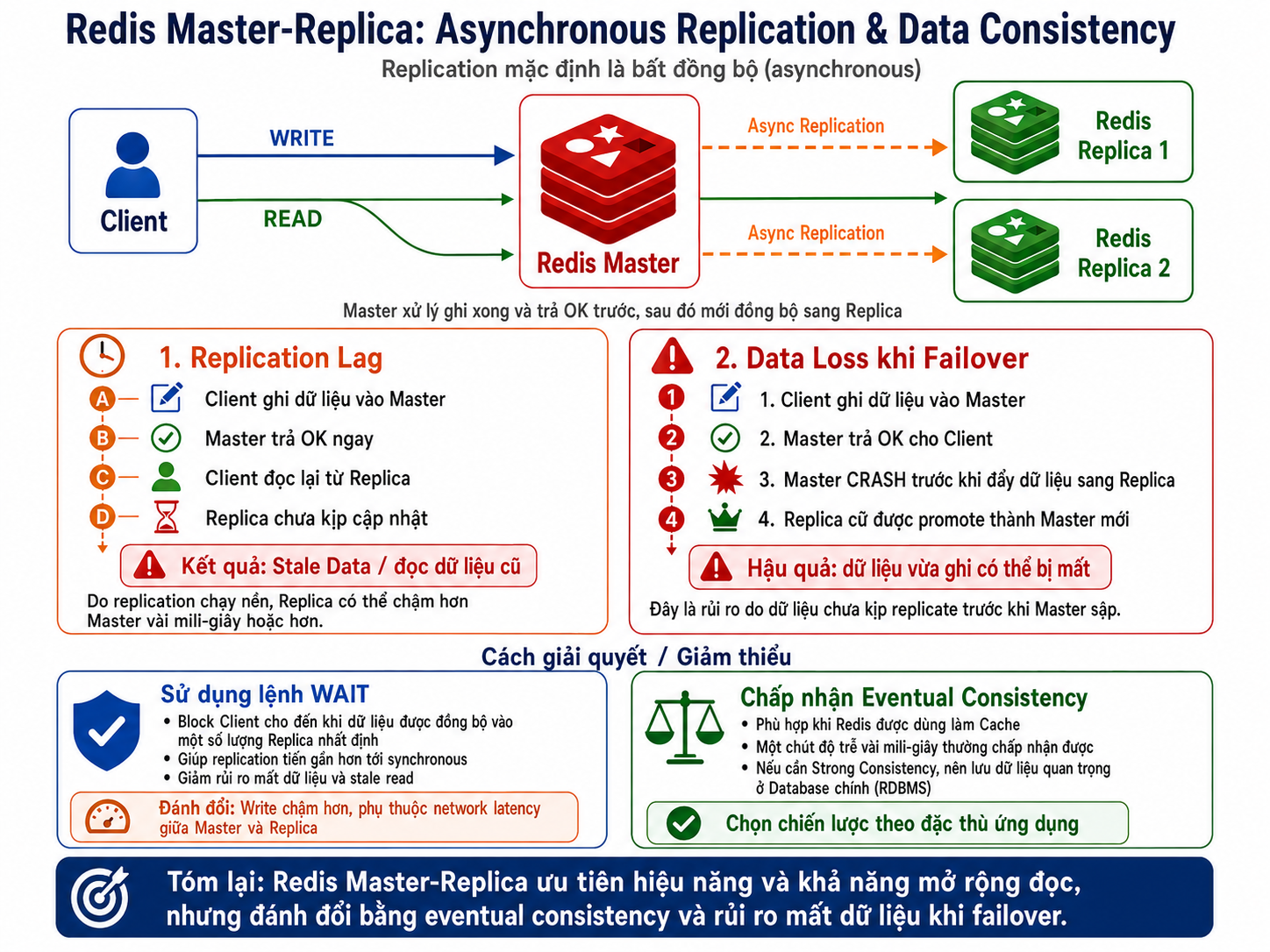
1. Replication Lag (Độ trễ nhân bản):
Khi Master nhận một lệnh Write, nó xử lý xong và trả về OK cho Client ngay lập tức, sau đó mới gửi lệnh này sang cho Replica.
Nếu Client ghi dữ liệu vào Master và ngay lập tức đọc lại từ Replica, có thể gặp trường hợp Replica chưa kịp cập nhật (Replication Lag), dẫn đến việc Client đọc được dữ liệu cũ (Stale data).
2. Mất dữ liệu khi Master sập (Data Loss trong quá trình Failover): Vì quá trình gửi dữ liệu cho Replica diễn ra ở background (sau khi đã báo thành công cho Client), nếu Master bị crash ngay sau khi trả lời Client nhưng chưa kịp đẩy dữ liệu sang Replica, lượng dữ liệu này sẽ bị mất khi hệ thống phong một Replica cũ lên làm Master mới.
Cách giải quyết / Giảm thiểu:
- Sử dụng lệnh
WAIT: Redis hỗ trợ lệnhWAITđể block Client cho đến khi dữ liệu được đồng bộ thành công vào một số lượng Replica nhất định. Điều này biến quá trình nhân bản tiến gần hơn tới đồng bộ (synchronous). Tuy nhiên, đánh đổi lại là tốc độ Write sẽ giảm đáng kể và bị phụ thuộc vào network latency giữa Master và Replica. - Chấp nhận rủi ro theo đặc thù ứng dụng (Eventual Consistency): Trong đa số trường hợp dùng Redis làm Cache, một chút độ trễ (vài mili-giây) là hoàn toàn chấp nhận được. Nếu dữ liệu yêu cầu tính Consistency tuyệt đối (Strong Consistency), bạn nên cân nhắc lưu trữ dữ liệu đó ở Database chính (RDBMS) thay vì chỉ phụ thuộc vào Redis.
2. Redis Sentinel (High Availability)
Lưu ý: Sentinel không phải là một kiến trúc độc lập thay thế cho Master-Replica. Thực chất, nó là một lớp quản lý (management layer) được gắn thêm vào trên nền tảng kiến trúc Master-Replica.
Ở phần trước, nhược điểm chí mạng của Master-Replica là bạn phải tự tay can thiệp khi Master sập. Để tự động hóa quá trình "thức dậy lúc 3h sáng" đó, Redis cung cấp công cụ Sentinel.
Redis Sentinel bao gồm các tiến trình chạy ngầm làm nhiệm vụ "lính gác". Chúng giám sát liên tục hệ thống Master-Replica hiện tại của bạn.
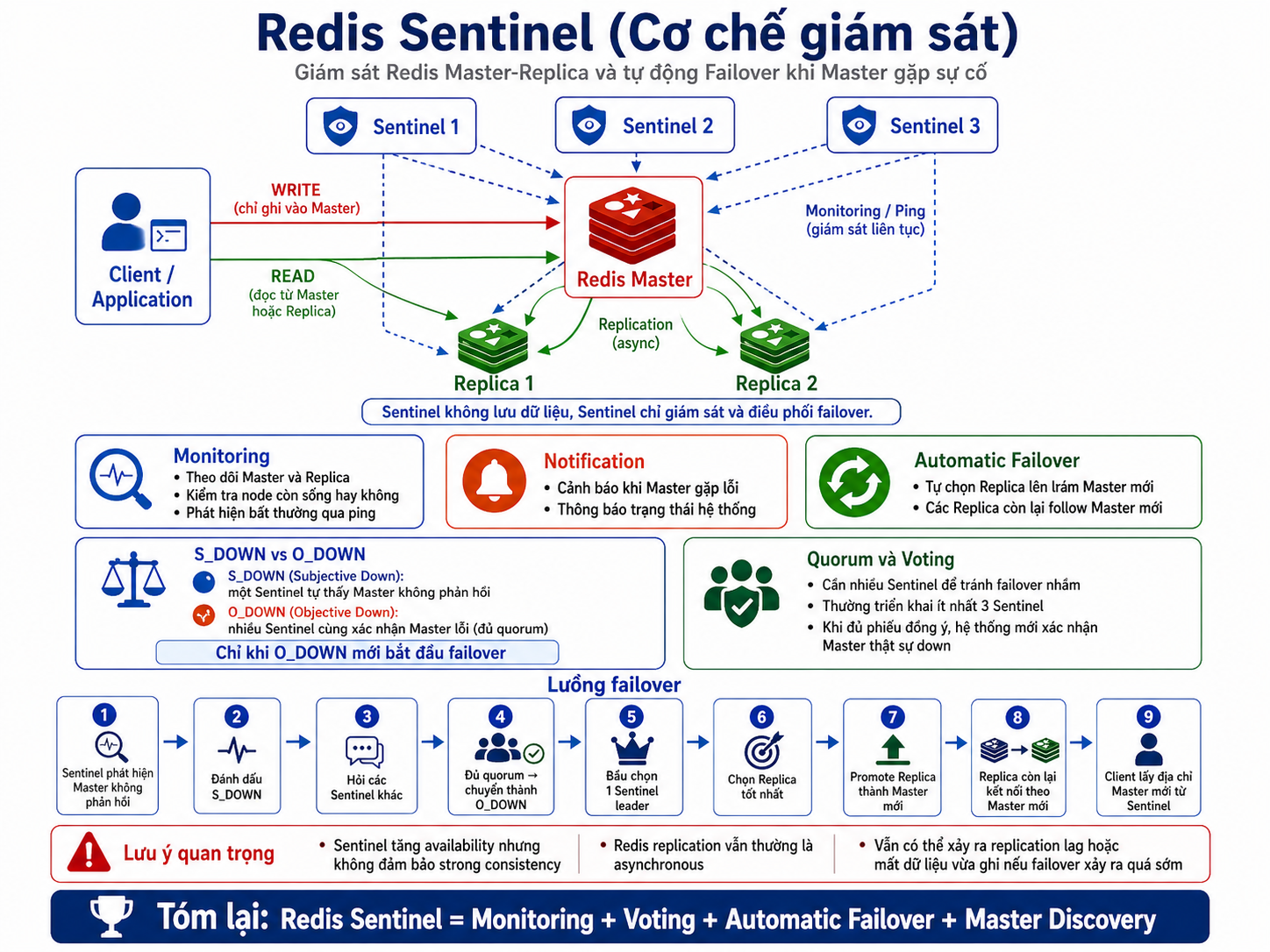
Cách hoạt động:
- Giám sát (Monitoring): Sentinel liên tục ping tới Master và Replica để kiểm tra xem chúng còn sống không.
- Thông báo (Notification): Nếu phát hiện Master chết, nó báo cho các hệ thống khác.
- Bầu chọn (Election): Nhóm Sentinel sẽ họp (theo cơ chế đa số - Quorum) để xác nhận Master thực sự đã chết.
- Tự động Failover: Sentinel tự động phong chức cho một node Replica khỏe nhất lên làm Master mới. Sau đó cập nhật lại cấu hình và báo cho ứng dụng (Client) biết địa chỉ IP của Master mới.
Một câu hỏi kinh điển thường gặp khi thiết kế hệ thống là: Giữa nhiều node Replica, Sentinel sẽ chọn node nào để làm Master mới?
💡 Tiêu chí bầu chọn Master mới của Sentinel: Sentinel sẽ không chọn ngẫu nhiên mà đánh giá các Replica dựa trên các tiêu chí sau (theo thứ tự ưu tiên):
- Tình trạng kết nối: Bỏ qua các Replica đang bị mất kết nối hoặc phản hồi quá chậm.
- Replica Priority (Độ ưu tiên): Chọn node có
replica-prioritythấp nhất (do bạn thiết lập trong file cấu hình). Lưu ý: Nếu gánreplica-priority = 0, node đó sẽ không bao giờ được lên làm Master.- Replication Offset (Mức độ cập nhật dữ liệu): Nếu các node có cùng priority, Sentinel sẽ chọn node có offset lớn nhất. Nói cách khác, Replica nào đồng bộ được nhiều dữ liệu nhất từ Master cũ (tức là dữ liệu mới nhất) sẽ thắng.
- Run ID: Nếu cả priority và offset đều bằng nhau, Sentinel sẽ chọn Replica có Run ID (chuỗi định danh ngẫu nhiên khi khởi động) theo thứ tự từ điển nhỏ nhất.
Ưu điểm:
- High Availability (Tính sẵn sàng cao): Chết Master hệ thống tự phục hồi trong vài giây, không cần can thiệp bằng tay.
Nhược điểm:
- Hơi tốn tài nguyên: Bạn cần chạy ít nhất 3 node Sentinel để tránh hiện tượng Split-Brain (Chia rẽ phiếu bầu).
- Vẫn chưa giải quyết được bài toán Scale-out ghi: Tất cả lệnh Write vẫn chỉ đổ về một con Master duy nhất.
3. Redis Cluster (Sharding & Khả năng mở rộng)
Redis Cluster là kiến trúc phù hợp khi cần mở rộng dung lượng, throughput và khả năng chịu lỗi bằng cách chia nhỏ dữ liệu thành nhiều hash slot nằm trên nhiều Master khác nhau.
1. Khái niệm:
- Redis Cluster thực chất là sự kết hợp của nhiều cụm Master + Replica.
- Toàn bộ không gian dữ liệu được chia làm tổng cộng 16,384 hash slots.
- Ví dụ:
- Master A giữ Slot 0 - 5460 (kèm theo Replica A1)
- Master B giữ Slot 5461 - 10922 (kèm theo Replica B1)
- Master C giữ Slot 10923 - 16383 (kèm theo Replica C1)
2. Cơ chế hoạt động:
- Client gửi request đọc/ghi một key bất kỳ (VD:
user:1). - Redis băm (Hash) key này để tính toán xem nó rơi vào slot nào.
- Tìm xem Master nào đang phụ trách slot đó.
- Request được gửi thẳng tới đúng node Master.
- Master xử lý yêu cầu và đồng bộ (replicate) dữ liệu sang node Replica của nó.
(Lưu ý: Nếu Client gửi request nhầm sang một node không chứa slot đó, node sẽ không xử lý mà trả về lỗi
MOVEDkèm theo địa chỉ IP của Master đích).
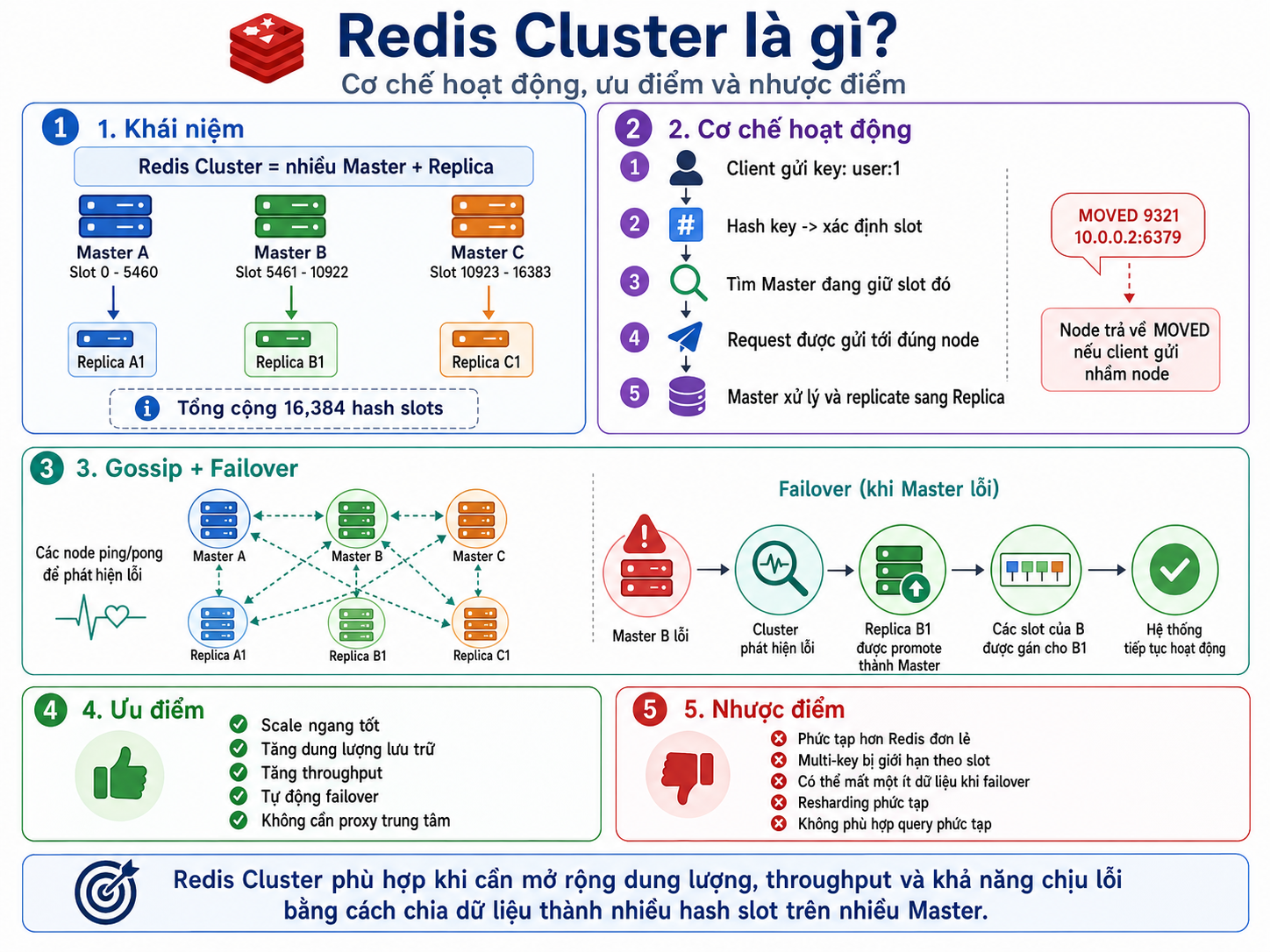
3. Gossip Protocol & Failover (Tự động phục hồi lỗi):
Khác với mô hình Master-Replica truyền thống phải dựa vào một bên thứ 3 (như Sentinel) để giám sát, các node trong Redis Cluster tự quản lý lẫn nhau thông qua một giao thức mạng ngang hàng (P2P) gọi là Gossip Protocol.
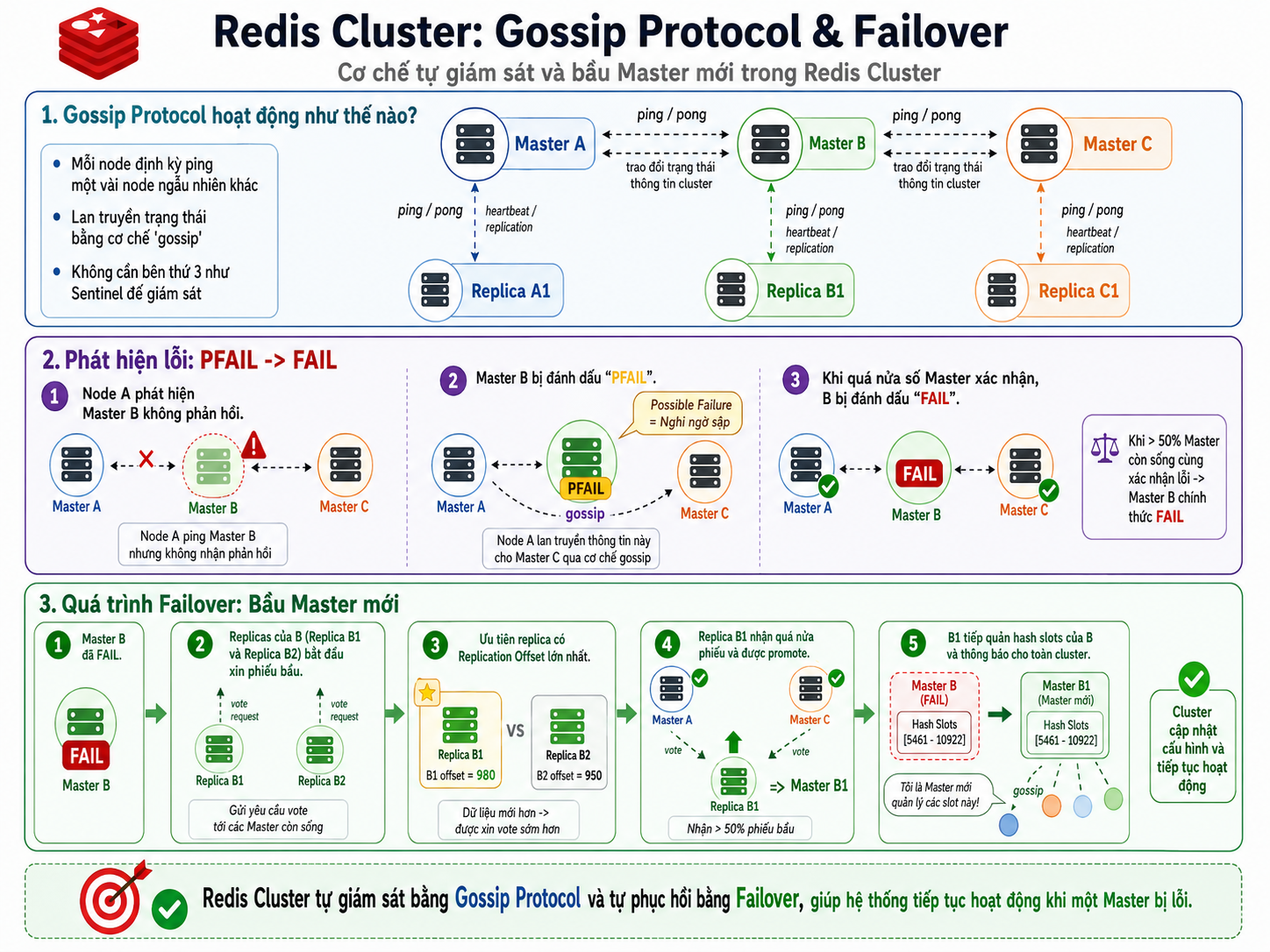
-
Gossip Protocol hoạt động như thế nào? Giống như cách những lời đồn (gossip) lan truyền trong đám đông, cứ mỗi giây, một node sẽ "ping" tới một vài node ngẫu nhiên khác trong Cluster để trao đổi thông tin cấu hình và trạng thái. Nếu Node A phát hiện Master B không phản hồi, nó sẽ tạm đánh dấu B là
PFAIL(Possible Failure - Nghi ngờ sập) và "bơm" tin đồn này cho các node khác. Khi có quá nửa số Master trong cụm cùng xác nhận B không phản hồi, Master B chính thức bị dán nhãn làFAIL(Đã sập). -
Quá trình Failover (Bầu Master mới):
- Khi Master B bị dán nhãn
FAIL, các Replica của B (ví dụ: Replica B1, B2) sẽ nhận ra sếp của mình đã chết và chúng bắt đầu một cuộc "bầu cử". - Các Replica này gửi thông điệp xin phiếu bầu (vote) tới tất cả các Master còn sống trong Cluster (như Master A, Master C).
- Để tránh tình trạng phiếu bầu bị chia nhỏ, Replica nào có Replication Offset lớn nhất (tức là nắm giữ dữ liệu cập nhật mới nhất từ Master cũ) sẽ được "châm chước" cho xin vote trước.
- Ngay khi Replica B1 nhận được sự đồng thuận của quá nửa số Master còn sống, nó chính thức được "promote" lên làm Master mới.
- B1 tự động tiếp quản lại toàn bộ hash slots mà B để lại, sau đó gửi bản tin Gossip thông báo cho toàn mạng lưới: "Từ giờ tôi là Master mới quản lý các slot này!". Toàn hệ thống được cập nhật cấu hình và tiếp tục hoạt động bình thường.
- Khi Master B bị dán nhãn
4. Ưu điểm:
- Scale ngang rất tốt: Tăng dung lượng lưu trữ vượt quá giới hạn RAM của một máy vật lý.
- Tăng Throughput: Tải được chia đều ra nhiều máy chủ khác nhau.
- Tự động Failover: Tự phục hồi khi có node chết mà không cần dùng đến Sentinel.
- Không cần Proxy trung tâm: Kiến trúc phi tập trung giúp loại bỏ điểm nghẽn (bottleneck).
5. Nhược điểm:
- Kiến trúc và vận hành phức tạp hơn rất nhiều so với Redis đơn lẻ hay Master-Replica.
- Bị giới hạn thao tác Multi-key: Không thể gọi lệnh trên nhiều key cùng lúc (như
MGET,MSET,SUNION) nếu các key nằm trên những slot khác nhau. - Vẫn có khả năng mất một ít dữ liệu khi Failover do quá trình đồng bộ từ Master xuống Replica là bất đồng bộ.
- Quá trình chuyển đổi, chia lại dữ liệu (Resharding) khá phức tạp.
- Không phù hợp với các truy vấn phức tạp.
4. Tổng kết: So sánh 3 Kiến trúc Redis
Để dễ hình dung và ra quyết định thiết kế hệ thống, dưới đây là bảng so sánh tổng quan giữa 3 kiến trúc phổ biến nhất:
| Tiêu chí | Master-Replica | Redis Sentinel | Redis Cluster |
|---|---|---|---|
| Mục đích chính | Phân tải đọc (Read Scale) | Phục hồi lỗi tự động (High Availability) | Mở rộng toàn diện (Scale-out Write & Storage) |
| Tự động Failover | ❌ Không (Cần làm bằng tay) | ✅ Có (Mất vài giây) | ✅ Có (Tự động thông qua Gossip) |
| Khả năng Scale Đọc (Read) | ✅ Tốt (Thêm Replica) | ✅ Tốt (Giống Master-Replica) | ✅ Rất tốt (Phân tán trên nhiều Master) |
| Khả năng Scale Ghi (Write) | ❌ Kém (Chỉ ghi ở 1 Master) | ❌ Kém (Chỉ ghi ở 1 Master) | ✅ Rất tốt (Ghi phân tán trên nhiều Master) |
| Dung lượng lưu trữ | Bị giới hạn bởi RAM của 1 máy | Bị giới hạn bởi RAM của 1 máy | 🚀 Vô hạn (Bằng tổng RAM các máy cộng lại) |
| Độ phức tạp vận hành | ⭐ Dễ | ⭐⭐ Trung bình (Cần duy trì số lẻ node) | ⭐⭐⭐ Khó (Cấu hình slot, routing phức tạp) |
| Hỗ trợ lệnh Multi-key | ✅ Hỗ trợ đầy đủ | ✅ Hỗ trợ đầy đủ | ⚠️ Hạn chế (Các key phải nằm cùng hash slot) |
| Tính nhất quán dữ liệu | ⚠️ Eventual (Có thể đọc trễ data ở Replica) | ⚠️ Eventual (Nguy cơ mất data lúc Failover) | ⚠️ Eventual (Nguy cơ mất data lúc Failover) |
| Use-case khuyên dùng | App nhỏ, chấp nhận hệ thống có thể bị downtime một lúc | App Production tiêu chuẩn (E-commerce, SaaS) | Siêu hệ thống, Big Data (Discord, Twitter, v.v.) |
💡 Chốt lại, tôi nên chọn cái nào?
- Hầu hết các dự án ở môi trường Production tiêu chuẩn sẽ ưu tiên dùng Redis Sentinel (hoặc mua các dịch vụ Managed Redis có sẵn High Availability trên Cloud). Nó cân bằng hoàn hảo giữa tính ổn định, dễ vận hành và chi phí.
- Chỉ đụng tới Redis Cluster khi bạn có bài toán thực sự khổng lồ (hàng trăm GB Cache, hoặc chịu tải hàng trăm nghìn lượt Write mỗi giây) mà việc nhồi thêm RAM vào một con server (Scale-up) là bất khả thi hoặc quá tốn kém.
Phần tiếp theo (Phần 3) sẽ là nơi chúng ta áp dụng Redis vào giải quyết các bài toán lập trình cụ thể như: Distributed Lock, Rate Limiting, Pub/Sub, ...